SQL => Structured Query Language (구조화된 질의언어)
Clauses
실행순서
SELECT clauses
5
FROM c
1
[WHERE c
2
[GROUP BY c
3
[HAVING c
4
[ORDER BY c
6
oracle에서는 SELECT절과 FROM절 생략 불가.
**ORDER BY절은 SELECT절 다음에 실행된다. (마지막에 정렬하는 기능을 수행)
**SELECT 문의 기본문법 구조**
-- SELECT [DISTINCT] { *, column [AS] [alias], ... }
-- FROM <테이블명>
✔ To project all columns of the table
-- SELECT *
-- FROM table;
✔ To project only the specified columns of the table
-- SELECT column1[, column2, ..., columnN]
-- FROM table;
✔ 산술연산자의 활용 ( +, -, *, / )
-- SELECT column1 + column2 FROM table;
-- SELECT column1 - column2 FROM table;
-- SELECT column1 * column2 FROM table;
-- SELECT column1 / column2 FROM table;
✔ About SYS.DUAL table
-- SYS account owns this DUAL table.
-- If you don't need a table, the DUAL table needed.
참고로, MySQL/Mariadb/Postgresql 에서는 생략가능!
✔ 특정 컬럼에 alias(별칭) 만들기
-- SELECT column1 [[as] alias]
-- FROM table;
AS는 생략이 가능하다.
✔ To test alias including special characters or whitespaces
-- (Whitespace: 공백문자, 탭문자 등)
-- Caution) In this case, you should use double quotation mark ("")
✔ NULL 값 이해하기
-- 분석입장에서는, "결측치(Missing Value)"라고 함.
-- 이러한 결측치가 발생하는 경우는,
-- (1) 실험측정시, 측정이 안되는 경우
-- (2) 실험측정장치의 오동작
-- (3) 관찰로 얻어지는 경우라면, 관찰이 안된 경우
-- (4) 관찰자(사람)의 실수 등 다양함
-- ------------------------------------------------------
-- * Caution: To test NULL
commission_pct에 값이 없는 tuple의 경우, salary * 12 + commision_pct에도 값이 없게되는 상황이 발생.
✔ NULL 값의 기본값 처리 : NVL() 함수 사용하기
-- 결측치의 처리: 분석에서는, 결측치 처리가 매우 다양하고
-- 사용방법에 따라, 통계량이 변경되기 때문에
-- 매우 주의해서 처리함
--
-- 결측치 처리예: 대표값(= 특성값) - 평균/중위수/최빈값/
-- 합계/제거!/보간(interpolation)
-- ------------------------------------------------------
-- * Caution: To use NVL(column, defaultValue) built-in function
✔ Concatenation Operater : ||
-- SELECT column1 || column2
-- FROM table;
-- SELECT column || literal
-- FROM table;
-- SELECT column1 || literal || column2 || literal || column3
-- FROM table;
✔ To remove duplicated data ( 중복제거 )
-- SELECT DISTINCT column1[, column2, ..., columnN]
-- FROM table;
부서의 이름을 중복없이 가져오고싶은 경우 아래 이용
칼럼1과 칼럼2이 모두 같은 경우 중복이라 한다. (즉, 칼럼1의 데이터가 동일하지만 칼럼2의 데이터가 다른 경우는 중복이 아님)
✔ Comparison Operators ( 비교연산자 )
-- 1. operand1 = operand2
-- 2. operand1 != operand2,
-- operand1 <> operand2,
-- operand1 ^= operand2
-- 3. operand1 > operand2
-- 4. operand1 < operand2
-- 5. operand1 >= operand2
-- 6. operand1 <= operand2
자동형변환이 가능하지만, 가독성을 위해 웬만하면 강제형변환을 이용하자.
강제형변환 함수 to_date()
✔ BETWEEN AND
✔ IN Operators (집합연산자)
-- WHERE column IN ( value1, value2, ... )
1. 집합원소유형 : 숫자
-- 수학의 집합의 성질을 기억!
-- (중복 비허용, 순서를 보장하지 않는다)
위 IN을 이용한 연산과 같은 결과
2. 집합원소유형 : 문자열
3. 집합원소유형 : 날짜
vscode에서는 날짜포맷방식이 RR/MM/DD가 아니기 때문에, to_date함수로 강제형변환 후 연산해야 한다.
✔ LIKE Operators (패턴매칭연산자)
-- WHERE column LIKE <패턴>
-- ------------------------------------------------------
-- <패턴>에 사용가능한 Wildcard 문자들:
-- (1) % ( x >= 0, x: 문자개수 )
-- (2) _ ( x == 1, x: 문자개수 )
last_name에 b가 들어가야함. 하지만 반드시 b 앞에 한개의 문자가 와야한다. b 뒤에는 0개 이상의 문자가 온다.
job_id 안에 일반문자 ' _ ' 하나는 꼭 들어가야 한다.
✔ Logical Operators (논리연산자)
-- (1) AND (그리고) : 두 조건을 모두 만족하는 경우 TRUE!
-- (2) OR (또는) : 두 조건중, 한가지만 만족해도 TRUE!
-- (3) NOT (부정) : 지정된 조건이 아닌 데이터를 검색
1. AND
2. NOT
--> 뒤 연산식을 부정!
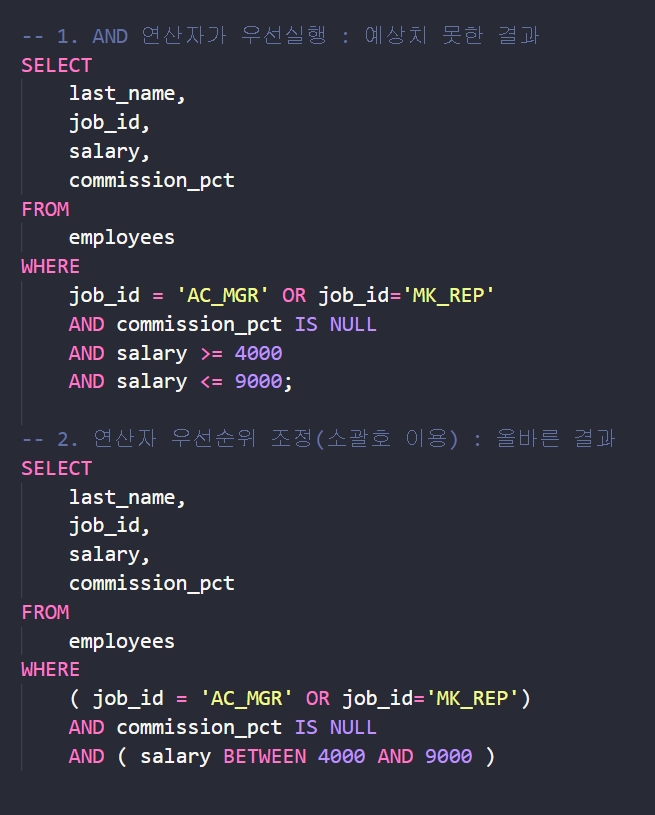
✔ 연산자 우선순위
--> 소괄호 잘 사용하자!
✔ --> 정렬
-- 문법)
-- SELECT [DISTINCT] {*, column [Alias], . . .}
-- FROM 테이블명
-- [ WHERE 조건식 ]
-- [ ORDER BY { column|표현식} [ASC|DESC] ];
--> ASC와 DESC 둘 다 없으면, Default는 ASC이다.
2. 문자데이터 정렬
3. 날짜데이터 정렬
4. 다중컬럼 정렬
-- SELECT [DISTINCT] {*, column [Alias], . . .}
-- FROM 테이블명
-- [WHERE 조건식]
-- ORDER BY
-- {column1|표현식1} [ASC|DESC], --> 첫번째 정렬 결과를 깨트리지 않고, 다음정렬을 수행한다.
-- {column2|표현식2} [ASC|DESC];
salary를 기준으로 내림차순 정렬 -> 그 후 hire_date를 기준으로 오름차순 정렬
---> 즉, 첫번째 정렬 결과에서, 같은 값이 나온 데이터에 대해 다음 정렬을 수행한다.
5. NULL값 정렬
(주의) Oracle 에서 가장 큰 값은, NULL 값임!!!
(값이 없기 때문에, 값의 크기를 비교불가)
따라서, 내림차순 정렬시, 가장 큰 값인 NULL 이 우선